N1904addons
Additional features for the N1904-TF, the syntactic annotated Text-Fabric dataset of the Greek New Testament.
About this datasetFeatureset
Loading the dataset
Using the Morpheus features
Latest release
N1904addons - Feature: md{num}_{inf_elem}
| Feature group | Feature type | Data type | Available for node types | Feature status |
|---|---|---|---|---|
Morpheus |
Node |
str |
word |
🆗 |
Feature description
Value for property {inf_elem} reported by Morpheus analysis block #{num}.
This is a Morpheus detail data feature.
Feature names and values
This page documents about 750 Text-Fabric features named like md3_case, md17_end_codes, md12_lem_full_uc or md1_morph. They collectively form the class of Morpheus detail features (more info).
The labels {num} and {inf_elem} are placeholders, which stand for:
{num}: The sequence number of a Morpheus analysis block, ranging from 1 to 24 (the maximum number of returned analysis blocks).{inf_elem}: One of the properties listed in the table below.
| Category | {inf_elem} | Data type | Description | Examples |
|---|---|---|---|---|
| Grammatical | case | str |
Slash separated list with grammatical case(s). | nom gen nom/voc/acc |
| degree | str |
Grammatical degree. | comparative |
|
| gender | str |
Slash separated list with grammatical gender(s). | masc neut masc/fem |
|
| mood | str |
Verb grammatical mood. | indicative participle |
|
| number | str |
Grammatical number. | sg dual pl |
|
| tense | str |
Verb grammatical tense | aorist present |
|
| voice | str |
Verb grammatical voice. | active middle/passive |
|
| Additional details | dialect | str |
Slash separated list of dialect(s). | attic doric/aeolic |
| morph_codes | str |
List of morp codes provided by Morpheus. | ||
| morph_flags | str |
List of morp flags provided by Morpheus. | indeclform ind/nu_movable |
|
| Wordform | aug1_bc | str |
(:aug) Augment mapping in betacode. | i)>ei) a)>h) |
| aug1_uc | str |
(:aug) Augment mapping in unicode. | ἰ>εἰ ἐ>ἠ |
|
| end_bc | str |
(:end) Wordform ending in betacode. | ous ws en |
|
| end_uc | str |
(:end) Wordform ending in unicode. | ες να εν |
|
| lem_base_bc | str |
(:lem) Base lemma in betacode. | *bi/blos ui(o/s |
|
| lem_base_uc | str |
(:lem) Base lemma in unicode. | ἀδελφός γεννάω |
|
| lem_full_bc | str |
(:lem) Full lemma in betacode (incl. homonym or pl marker). | *bi/blos ge/nesis |
|
| lem_full_uc | str |
(:lem) Full lemma in unicode (incl. homonym or pl marker). | Βίβλος γένεσις |
|
| lem_homonym | str |
(:lem) Set to '1' if this is a homonym lemma. | 1 <empty> |
|
| lem_pl_suffix | str |
(:lem) PL suffix of lemma (if '1' often proper or geographic name). | 1 <empty> |
|
| prvb_bc | str |
(:prvb) Space separated list of prepositions in betacode. | meta/ a)na/ su/n |
|
| prvb_uc | str |
(:prvb) Slash separated list of prepositions in unicode. | ἐκ/ἐπί πρός |
|
| stem_bc | str |
(:stem) Stem in betacode. | meta/ a)na/ su/n |
|
| stem_uc | str |
(:stem)Stem in unicode. | ἐκ ἐπί πρός |
|
| Codes and flags | end_codes | str |
(:end) Slash separated list of codes for ending (mainly references to endtables in stemlib). | os_ou os_ou/os_ou |
| end_flags | str |
(:end) Slash separated list of flags for ending (mainly additional morphological properties). | nu_movable contr |
|
| stem_codes | str |
(:stem) Slash separated list of morph codes for stem (mainly references to endtables in stemlib). | os_h_on aor1/aw_denom |
|
| stem_flags | str |
(:stem) Slash separated list of morph flags for stem (mainly additional morphological properties). | .. indeclform |
|
| Derived | gram_dif | str |
Field indicating grammatical differences with morph tag in N1904-TF. See also using the gram_dif feature. | lp.n.tmv. .cng.... |
| morph | str |
Slash separated list of derived morphtag(s) following Sandborg-Petersen morphology (comparable to feature morph in N1904-TF). | V-AAI-3S N-NDF/N-VDF/N-ADF |
|
| sp | str |
Determined Part of Speech (POS). (comparable to feature sp in N1904-TF). | verb preposition |
Using these features
The .tf files for these features are located at "N1904addons/detailed_set" and not standard part of the N1904addons. To use these features you need to load both the N1904addons and the detailed feature set.
To load both the ‘standard’ N1904addon features and the detailed_set, you need to invoking Text-Fabric like:
A = use ("CenterBLC/N1904", version="1.0.0", silence="terse", mod=["tonyjurg/N1904addons/tf/", "tonyjurg/N1904addons/detailed_set"], hoist=globals())
Programmatic access
There are several methods to access the features programmaticaly. One method is to use a variable as feature name in combination with the Fs(ffff) method:
for wordNode in wordNodeList
for block in range(1, 25):
feat = f"md{block}_gender" # e.g. "md5_gender"
gender = Fs(feat).v(wordNode)
This works fine when just looking up a few feature values. A more efficent approach is to first create a straight hash-table:
BLOCK_RANGE = range(1, 25)
gender_feat = {b: Fs(f"md{b}_gender") for b in BLOCK_RANGE}
for wordNode in wordNodeList
for block in range(1, 25):
gender = gender_feat[block].v(wordNode)
Both functions deliver the same result, but the second on is much faster, especialy if there are many iterations in the loop. See also ‘Using the Morpheus features’ or the associated Jupyter notebook.
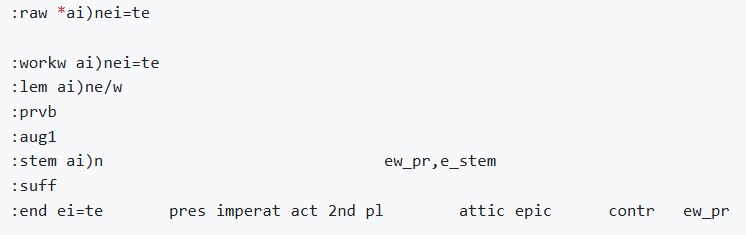
Morpheus analytic blocks
The following image shows an example of a Morpheus analyses block.