N1904addons
Additional features for the N1904-TF, the syntactic annotated Text-Fabric dataset of the Greek New Testament.
About this datasetFeatureset
Loading the dataset
Use cases
Latest release
Using the Morpheus features
This page first presents an overview of how Morpheus features are logically organized into classes. It then shows how that structure supports a practical workflow, guiding you from a high-level meta view, through a concise summary, and finally to a detailed inspection of the Morpheus data.
Morpheus feature classes
The total number of distinct Text-Fabric features related to the Morpheus morphological analysis is close to a thousand. Without a logical taxonomy this would be unable to handle. Therefore, the Morpheus related Text-Fabric features are devided into four main groups:
| Class | Naming patern | Function and maps to datatype |
|---|---|---|
| Meta | mm_{feature} | Word-level features containing meta data like details on number of lemmas returned for the analysis of a single word. This group also contains features that assist programmatic access to the summary features. |
| Summary | ms{ind}_{feature} | Word-level features containing a summary indexed per lemma of all related analytic blocks returned by Morpheus. This group also contains features that assist programmatic access to the detailed features. |
| Detail | md{ind}_{feature} | Word-level features providing access to (almost) all details in the Morpheus analytical blocks |
| Analytic | ma{ind}_{feature} | Phrase-level features derived from Morpheus analyses cross-referenced with N1904-TF morphosyntactic tags |
The figure below illustrates the overall structure of the three feature classes that link Morpheus analytical data to individual words.:
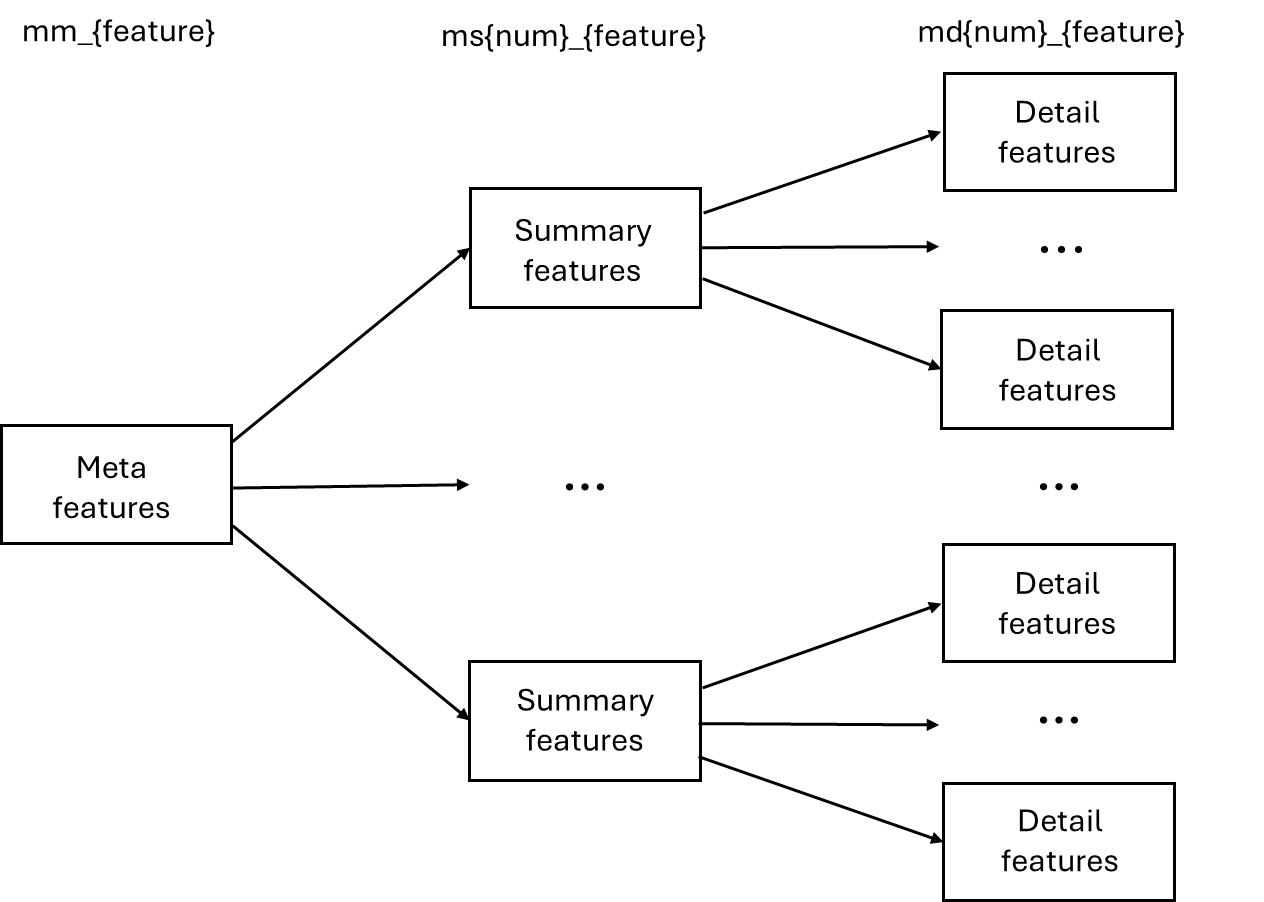
From the table and the image it is clear that the majority of feature will belong the to ‘detailed class. In many cases the level of detail therein is not required, since the summary of them is readily made available by means of the summary features. Therefore, the features in class ‘detail’ are not loaded by default when loading the N1904addons. If access is required, they can simply be loaded together with the N1904addons, using the following Python code:
A = use ("CenterBLC/N1904", version="1.0.0", silence="terse", mod=["tonyjurg/N1904addons/tf/", "tonyjurg/N1904addons/detailed_set"], hoist=globals())
In this case the option silense=”terse” may be realy helpfull in order to supress the huge output during loading and compiling of the large number of features. Take note that althoug loading may take some time, once loaded Text-Fabric is not significant slowed down by the huge number of features.
Guide: working with Morpheus feature-set in Text-Fabric
This section (which is also available as a downloadable Jupyter Notebook) will provide you a compact overview of how the concept of Morpheus TF feature classes is helpfull. The example below shows you how to begin at the meta level, drill down to the summary level, and—when needed—inspect the full, detailed analytic blocks. Everything happens within a single environment that brings together the core N1904-TF dataset, the N1904addons module, and optionaly a set of detailed functions when desired.
Step 1: Load N1904-TF with the Morpheus “standard” features
from tf.app import use
A = use( "CenterBLC/N1904", version="1.0.0", mod="tonyjurg/N1904addons/tf/", hoist=globals())
The mod argument above pulls the feature files straight from the GitHub repository behind N1904addons so no manual download is needed.
Step 2: Start at the meta level (mm*)
Suppose we want to understand how many wordforms be derived from a different lemmas. The first step could be to just create a frequency table:
F.mm_num_lemmas.freqList()
>>> ((1, 78324), # (number of lemmas, frequency)
>>> (2, 29104),
>>> ...
>>> (12, 6),
>>> (11, 1))
Now lets assume we would like to examine the wordforms that migth be derived from - say - exactly 9 lemmas. With a very simple TF Query template we can obtain a list of all wordnodes that provide us access to all these wordforms:
multiLemmaList=A.search("word mm_num_lemmas=9")
>>> 0.09s 42 results
The TF Query returns a list with 1-tuples which we now can examine further. So the next step is to get a frequency table of the surface forms:
from collections import Counter
cnt = Counter(
F.mm_raw_uc.v(wordNode) # surface form Morpheus analysed
for (wordNode,) in multiLemmaList # wordNodeList is a list of 1-tuples: [(wordNode,),]
)
Printing cnt shows 4 different wordforms: Διὰ (36 times), περάτων (twice), and the following words each once: ἀπόλωνται, Δία, διαπονηθεὶς, and διακονιῶν. Now assume we would like to dig deeper into the last wordform, διακονιῶν.
This means that we are looking at an unique occurence of a wordform. There are various methods to identify the value of its wordNode, which is the key to unlock all the data we would like to see. This one is a quick and easy one:
wordNodeList=A.search("word mm_raw_uc=διακονιῶν")
>>> 0.09s 1 result
As expected this returns a list with just one tuple. Now we can print some more details:
for (wordNode,) in wordNodeList: # wordNodeList is a list of 1-tuples: [(wordNode,),]
print(f'surface form Morpheus used: {F.mm_raw_uc.v(wordNode)}')
print(f'lemma groups found: {F.mm_num_lemmas.v(wordNode)}')
print(f'Total number of analytic blocks: {F.mm_num_blocks.v(wordNode)}')
>>> surface form Morpheus used: διακονιῶν
>>> lemma groups found: 9
>>> Total number of analytic blocks: 15
Step 3: Explore at the summary level (ms*)
To examine these 9 lemmas and their respective grammatical details (like morph code) in detail we need to turn to the summary features. This can easily be done using simple Python code. The real trick in there is the use of a variable name that is constructed dynamicaly in combination with using Text-Fabric’s Fs('fff') method:
First we exploit the power of the summary features by printing for each lemma the associated morphological tags which provide a very consise summary of all the grammatical detailed created by Morpheus.
for (wordNode,) in wordNodeList: # wordNodeList is a list of 1-tuples: [(wordNode,),]
# How many lemma-groups does this word actually have
n_lemmas = int(F.mm_num_lemmas.v(wordNode) or 0)
# loop over the existing groups 1 … n_lemmas
for index in range(1, n_lemmas + 1):
lemma = Fs(f"ms{index}_lem_base_uc").v(wordNode) # e.g. "ms1_lem_base_uc"
morph = Fs(f"ms{index}_morph").v(wordNode)
sim = Fs(f"ms{index}_morph_sim").v(wordNode)
print(f"#{index}: lemma={lemma:12} morph={morph} sim={sim}")
>>> #1: lemma=διακονία morph=N-GPF sim=100
>>> #2: lemma=διακόνιον morph=N-GPN sim=92
>>> #3: lemma=διά-ἀκονάω morph=V-PAP-NSM sim=49
>>> #4: lemma=διά-κονέω morph=V-PAP-NSM sim=49
>>> ...
>>> #8: lemma=διά-κονιάζω morph=V-FAP-VSM/V-FAP-NSN/V-FAP-VSN/V-FAP-ASN/V-FAP-NSM sim=49/49/49/49/49
>>> #9: lemma=διακονέω morph=V-PAP-NSM sim=49
Step 4 : Deep dive at the detail level (md*)
When we want to dig one level deeper, we should dump the data in feature ms{ind}_block_nums, as this allows us to map the summary features (which are numbered) with their related detailed features (which are also numbered but with a different key).
for (wordNode,) in wordNodeList: # wordNodeList is a list of 1-tuples: [(wordNode,),]
# How many lemma-groups does this word actually have
n_lemmas = int(F.mm_num_lemmas.v(wordNode) or 0)
# loop over the existing groups 1 … n_lemmas
for index in range(1, n_lemmas + 1):
feat = f"ms{index}_block_nums" # e.g. "ms1_block_nums"
block_nums = Fs(feat).v(wordNode) # Text-Fabric feature lookup
if block_nums: # skip empty slots
print(f"lemma #{index} uses blocknumbers {block_nums}")
>>> lemma #1 uses blocknumbers 1
>>> lemma #2 uses blocknumbers 2
>>> ...
>>> lemma #7 uses blocknumbers 7/8/9/10/11
>>> lemma #8 uses blocknumbers 12/13/14
>>> lemma #9 uses blocknumbers 15
Now we can pull from the Morpheus analytic blocks any detailed grammatical property we would like to evaluate. But in order to be able to use these detailed features, we need to load them first. For this we reload again with inclusion on the detailed dataset:
# reload with detailed_set ------------------------------------
A = use( "CenterBLC/N1904", version="1.0.0", mod=["tonyjurg/N1904addons/tf/", "tonyjurg/N1904addons/detailed_set"], hoist=globals(), silence="terse",)
Now we can create tables using specific part of the Morpheus output. For example aspects like preposition, stem, lemma and ending for each analysis block:
wordNodeList=A.search("word mm_raw_uc=διακονιῶν") # we have to re-do this since we reloaded!
for (wordNode,) in wordNodeList: # wordNodeList is a list of 1-tuples: [(wordNode,),]
# How many lemma-groups does this word actually have
n_lemmas = int(F.mm_num_lemmas.v(wordNode) or 0)
# loop over the existing groups 1 … n_lemmas
for index in range(1, n_lemmas + 1):
feat = f"ms{index}_block_nums" # e.g. "ms1_block_nums"
block_nums = Fs(feat).v(wordNode) # Text-Fabric feature lookup
block_list = split(block_nums,'/')
print(f'index={index} blocks={block_nums}')
for block in block_list:
lem_base_uc = Fs(f"md{block}_lem_base_uc").v(wordNode)
prvb_uc = Fs(f"md{block}_prvb_uc").v(wordNode)
stem_uc = Fs(f"md{block}_stem_uc").v(wordNode)
ending_uc = Fs(f"md{block}_ending_uc").v(wordNode)
Now making it efficient
In the previous example, just a few lookups were performed. Access to the detailed features can be made dramaticlay more efficient. In the above situation, Text-Fabric needs to resolve the string name we passed (for example “md7_workw_bc”) into an immutable feature object that it knows how to fetch the value for any node. Doing that name-lookup 24 × ≈138 000 word-nodes = about 3.3 million calls.
Especialy if we need to perform such actions multiple times, we can better caching the result once per block, thus making it 24 calls total, and then access it with a simple .v(node) method. This caching can be done using the following code:
BLOCK_RANGE = range(1, 25)
lem_base_uc_feat = {b: Fs(f"md{b}_lem_base_bc") for b in BLOCK_RANGE}
prvb_uc_feat = {b: Fs(f"md{b}_prvb_uc") for b in BLOCK_RANGE}
What we created here are just two straight hash-tables lem_feat[b] and workw_feat[b] (where b is the block number in the range of 1 to 24, inclusive). Now the lookups are very simple to perform:
lem_base_uc = lem_base_uc_feat[b].v(wordNode)
prvb_uc = prvb_uc_feat[b].v(wordNode)
Putting it all together in a working example where we would like to do something with the combination of lemma and working word for all Morpheus analytic blocks.
# Once, before the big loop, cache the md* features we would like to access
BLOCK_RANGE = range(1, 25)
lem_feat = {b: Fs(f"md{b}_lem_full_bc") for b in BLOCK_RANGE}
workw_feat = {b: Fs(f"md{b}_workw_bc") for b in BLOCK_RANGE}
import time
t0 = time.perf_counter() # start timer
counter=0
# Now fire up our word nodes loop
for wordNode in F.otype.s("word"):
# quickly collect (lemma, workw) pairs for this word
for block in BLOCK_RANGE:
lem = lem_feat[block].v(wordNode)
if not lem: # skip empty Morpheus slots fast
continue
workw = workw_feat[block].v(wordNode)
counter +=1
# do something interesting with (lem, workw)
elapsed = time.perf_counter() - t0 #stop timer
print(f"Processed {counter:,} lemma–workw pairs in {elapsed:.2f} s ({counter/elapsed:,.0f} pairs/s)")
>>> Processed 361,580 lemma–workw pairs in 0.74 s (487,831 pairs/s)
This three-tier approach keeps the usual workflow not only fast and lightweight (meta + summary only) while it also gives you fast access to any deep level information your research question demands.
More examples
Feature scanning across multiple morpheus blocks
Building on the previous code, the following example demonstrates how to search through the outputs of each Morpheus analysis block to find all word nodes that match a given lemma and begin with a specific morphological code segment.
BLOCK_RANGE = range(1, 25)
lem_feat = {b: Fs(f"md{b}_lem_base_uc") for b in BLOCK_RANGE}
morph_feat = {b: Fs(f"md{b}_morph") for b in BLOCK_RANGE}
for wordNode in F.otype.s('word'):
for block in BLOCK_RANGE:
if lem_feat[block].v(wordNode)=="ἄρχω" and "V-PAP-G" in morph_feat[block].v(wordNode):
print (T.sectionFromNode(wordNode),f'{block=}', morph_feat[block].v(wordNode))
('Matthew', 9, 23) block=2 V-PAP-GSM/V-PAP-GSN
('Luke', 14, 1) block=2 V-PAP-GPM/V-PAP-GPN
('John', 7, 48) block=2 V-PAP-GPM/V-PAP-GPN
('John', 12, 42) block=2 V-PAP-GPM/V-PAP-GPN
('I_Corinthians', 2, 6) block=2 V-PAP-GPM/V-PAP-GPN
('I_Corinthians', 2, 8) block=2 V-PAP-GPM/V-PAP-GPN