N1904addons
Additional features for the N1904-TF, the syntactic annotated Text-Fabric dataset of the Greek New Testament.
About this datasetFeatureset
Loading the dataset
Using the Morpheus features
Latest release
N1904addons - Feature: ms{num}_lem_full_bc
| Feature group | Feature type | Data type | Available for node types | Feature status |
|---|---|---|---|---|
Morpheus |
Node |
int |
word |
✅ |
Feature description
Summary feature for grouped analysis #{num} providing the full lemma (incl. homonym or pl-suffix identifiers, if any) encoded in betacode.
This is a Morpheus summary data feature.
Feature values
The lemma string in unicode.
Coding
The following Python code demonstrates how to programaticaly obtain details like lemma and morphological tags per grouped analysis blocks.
NEED TO CHECK
wordNodes = F.otype.s("word")
for wordNode in wordNodes:
for blockNumber in range(1, 9):
# dynamically get F.ms{blockNumber}_lemma & morph
lemma = Fs(f"ms{blockNumber}_lem_").v(wordNode)
if not lemma: continue
morph_string = Fs(f"ms{blockNumber}_morph").v(wordNode)
morph_sim_string = Fs(f"ms{blockNumber}_morph_sim").v(wordNode)
# decompose on the slash
parts = morph_string.split("/")
# print what was found
print(f"node={wordNode}, number={blockNumber} → lemma={lemma}, tags: {parts}")
node=1, number=1 → lemma=Βίβλος, tags: ['N-NSM']
node=1, number=2 → lemma=βίβλος, tags: ['N-NSF']
node=2, number=1 → lemma=γένεσις, tags: ['N-GSF']
node=3, number=1 → lemma=Ἰησοῦς, tags: ['N-GSM', 'N-VSM', 'N-PRI']
...
The snippet below dynamicaly builds a list of names of ‘numbered’ Morpheus feature names. This allows to easily pass this list as an option to A.show()
# Dynamically generate feature names for all morphology sets
morphFeatureList = (
[f'ms{i}_lemma' for i in range(1, 9)]
+ [f'ms{i}_morph' for i in range(1, 9)]
+ [f'ms{i}_morph_sim' for i in range(1, 9)]
)
# Display the query results with the Morpheus features
A.show(QueryResult, extraFeatures=morphFeatureList)
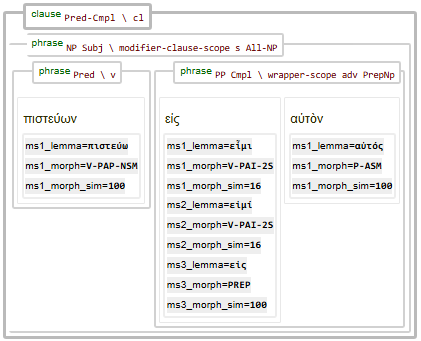
The image below shows a syntax tree with the display of these features enabled.