N1904addons
Additional features for the N1904-TF, the syntactic annotated Text-Fabric dataset of the Greek New Testament.
About this datasetFeatureset
Loading the dataset
Use cases
Latest release
N1904addons - Feature: morph_entr_norm
| Feature group | Feature type | Data type | Available for node types | Feature status |
|---|---|---|---|---|
statistic |
Node |
int |
word |
✅ |
Feature short description
Normalized Shannon entropy of the distribution of parent phrase function (like Subject, Object, etc.) for each morph(-tag of a word).*
*) For the calculation of entropy the dialect tag (like -ATT) was ignored.
Feature values
A number stored as an integer representing the entropy normalized to a range from 0 to 1000 (inclusive).
Feature detailed description
In practical terms, entropy reflects how predictable an element’s syntactic behavior is predictable. This feature expresses how consistently a given lemma (as stored in the morph feature) maps to a particular phrase function.
In this context these phrase functions are derived from feature function and expanded with several additional categories (to view all details expand the item below).
Parent phrase function details
In the N1904-TF dataset, not all words belong to phrases with well-defined syntactic functions such as Subject or Object. For instance, conjunctions like δὲ or καὶ typically do not form part of syntactic phrases in the strict sense.
To ensure that every word can still be assigned a functional label, the following Python script was developed. This script prioritizes assigning the canonical phrase function where available, but also supplements gaps with a set of extended categories.
The table below distinguishes between these two types of categories and shows the number of word nodes mapped to each one.
| Source | Value | Description | Frequency |
|---|---|---|---|
From feature function (6 classes) |
Cmpl | Complement | 35442 |
| Pred | Predicate | 25138 | |
| Subj | Subject | 21567 | |
| Objc | Object | 19371 | |
| PreC | Predicate-Complement | 9595 | |
| Adv | Adverbial | 5367 | |
| Augmented pseudo classes (5 classes) | Conj | Conjunction | 16316 |
| Unkn | Unknown | 2076 | |
| Intj | Interjection | 1470 | |
| Aux | Auxiliar | 1136 | |
| Appo | Apposition | 301 |
The "Unkn" (unknown) category accounts for approximately 1.5% of all mappings, slightly raising both the absolute and normalized entropy.
High entropy values indicate that a form is ambiguous, as it appears in multiple syntactic functions with similar probabilities. In contrast, low entropy values signify that a form is strongly associated with a single syntactic function, making it a reliable indicator of that role within the parent phrase.
Detailed mathematic description
Definition
In information theory, entropy quantifies how unpredictable the outcome of a random variable is. For a discrete variable \( X \) with possible outcomes \( x_1, x_2, ... x_n \) and corresponding probabilities \( p_1, p_2, ... p_n \), the Shannon entropy is defined as:
$$H(X) = -\sum_{i=1}^{n} p(i) \log_2 p(i)$$The logarithm base 2 expresses the result in bits. By convention, the term \( p_i\,\log_2 p_i \) is taken to be zero when \( p_i=0 \), so that only outcomes with non‑zero probability contribute to the sum.
Entropy is maximised when all outcomes are equally likely (i.e., uniform distribution), and drops to zero when a single outcome has probability 1 and all others have probability 0 (i.e. when there is no uncertainty at all).
Application
In this Text-Fabric dataset the phrase function (the syntactic role of a word’s parent phrase) s treated as a discrete random variable \( F \). We examine how much information a given linguistic cue \( c \) (such as text , lemma, or morph) provides about the likely syntactic role of an occurrence of that cue.
For a specific cue \( c \), the empirical conditional distribution \( p(f \mid c) \) is calculated, which reflects how frequently the cue occurs with each phrase function \( f \) in the data. Based on this distribution, the conditional entropy can be calculated as:
$$H(F \mid c) = -\sum_{f \in \mathcal{F}} p(f \mid c) \log_2 p(f \mid c)$$This quantity measures the uncertainty about the phrase function of a single occurrence of the cue \( c \), once the cue is known. It does not aggregate across different cues or sum over positions; rather, it characterizes how predictable the syntactic role is for any individual instance of the cue.
- A low value of \( H(F \mid c) \) indicates that the cue \( c \) strongly predicts a particular phrase function (e.g., it almost always functions as Subject).
- A high value indicates that the cue appears in multiple syntactic roles with similar probabilities, making its function hard to predict.
In the Text-Fabric features, these entropy values are multiplied by 1000 and rounded to the nearest integer (i.e., scaled to millibits) to avoid storing floating-point numbers, while preserving reasonable precision.
To obtain a normalized entropy, the absolute entropy values were devided by \( log_2(11) \), the maximum absolute value for entropy.
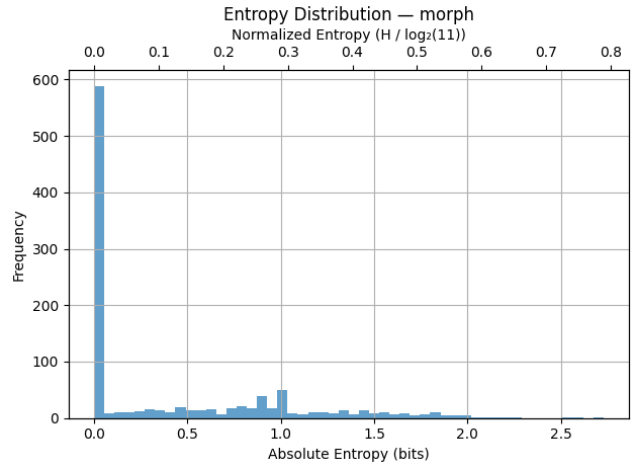
The following table provides some statistic key metrics for this feature counted over the total of 1055 unique morphs:
=== morph ===
Count: 1018
Min: 0000
25%ile: 0000
Median: 0000
75%ile: 0254
Max: 0788
Mean: 0125
StdDev: 0168
This indicates that most morphs are highly predictable in terms of their syntactic roles, while a small subset show high entropy due to usage in multiple phrase functions.
The following plot illustrates both the absolute and normalized entropy distribution for all 1055 unique morph tag in the N1904-TF dataset:
Theoretical example
To better understand the significance of entropy values, the following plot illustrates the absolute entropy associated with several synthetic probability distributions.
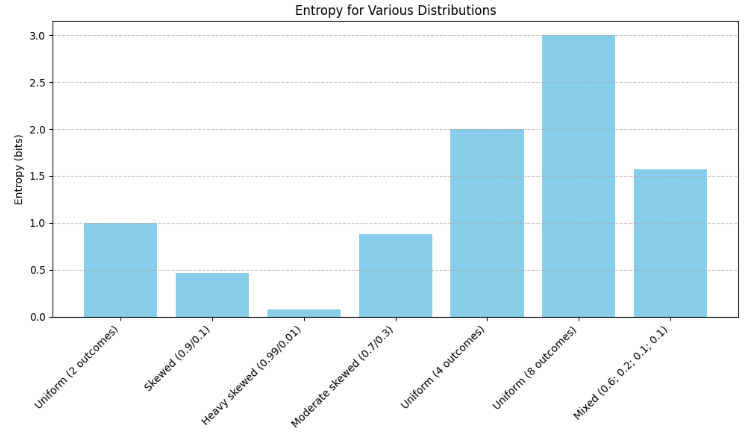
The information can also be presented in a table augmented with the values for normalized entropy. In the example above, we assumed a total of 8 possible classes. Therefore, to compute the normalized entropy, we can simply divide each absolute entropy by 3, since since \( \log_2(8) \) = 3.
| Distribution | Absolute entropy (bits) | Normalized entropy (8 classes) |
|---|---|---|
| Uniform (2 outcomes) | 1.0000 | 0,3333 |
| Skewed (0.9, 0.1) | 0.4689 | 0.1563 |
| Heavy skewed (0.99, 0.01) | 0.0808 | 0.1563 |
| Moderate skewed (0.7, 0.3) | 0.8813 | 0.2938 |
| Uniform (4 outcomes) | 2.0000 | 0.667 |
| Uniform (8 outcomes) | 3.0000 | 1.0000 |
| Mixed (0.6, 0.2, 0.1, 0.1) | ~1.6855 | ~0.5618 |
This highlight the following key properties of entropy:
- Entropy increases with the number of equally likely outcomes.
- Entropy decreases when one outcome dominates the distribution.
See also
Related features
- morph_entr: Absolute entropy of a morph(-tag of a word) as predictor of its parent phrase function (in bits).
- lemma_entr: Absolute entropy of the lemma (of this word) as predictor of its parent phrase function (in bits)
- text_entr: Absolute entropy of a surface level wordform as predictor of its parent phrase function (in bits).
- lemma_entr_norm: Normalized entropy of the lemma (of this word) as predictor of its parent phrase function (range 0 to 1).
- text_entr_norm: Normalized entropy of a surface level wordform as predictor of its parent phrase function (range 0 to 1).
References
- Shannon, C. E. “A Mathematical Theory of Communication” in Bell System Technical Journal, Vol. 27, pp. 379–423, 623–656, July, October, 1948.
- Manning, C. D., Schütze, H. Foundations of Statistical Natural Language Processing (Cambridge, MA: MIT Press, 1999), esp. page 61 and further.
Data source
GitHub repository Create-TF-entropy-features.